


We assisted a Fintech client to minimize its storage cost by archiving its data from RDS (MySQL) to S3 using an automated batch process, where all data from a specific time range should be exported to S3. Once the data is stored on S3 the historical data can be analyzed using AWS Athena and Databricks. The solution should include a delete strategy to remove all data older than two months.
Currently, the database size has increased exponentially with the number of logs that are stored in the database, this archive procedure should have a minimal impact on the production workload and be easy to orchestrate, for this specific data archiving case we are handling tables with more than 6 TB of data which should be archived in the most efficient manner, part of this data will no longer be necessary to be stored on the database.
In this scenario, Managed Workflows for Apache Airflow (MWAA), a managed orchestration service for Apache Airflow, helps us to manage all those tasks. Amazon MWAA fully supports integration with AWS services and popular third-party tools such as Apache Hadoop, Presto, Hive, and Spark to perform data processing tasks.
In this example, we will demonstrate how to build a simple batch processing that will be executed daily, getting the data from RDS and exporting it to S3 as shown below.
Export\Delete Strategy:
- The batch routine should be executed daily
- All data from the previous day should be exported as CSV
- All data older than 2 months should be deleted
Solution
- RDS – Production database
- MWAA – (to orchestrate the batches)
- S3 bucket – (to store the partitioned CSV files)
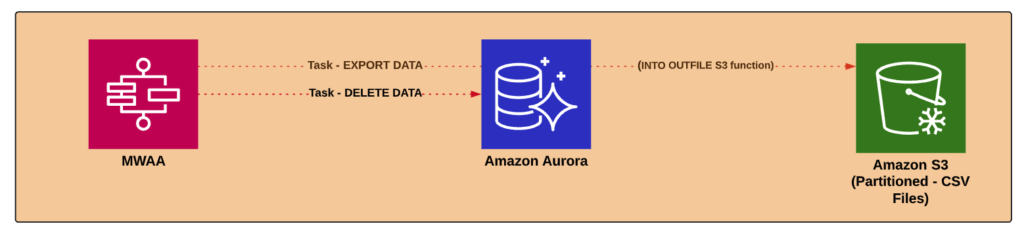
As shown in the architecture above, MWAA is responsible for calling the SQL scripts directly on RDS, in Airflow we use MySQL operator to execute SQL scripts from RDS.
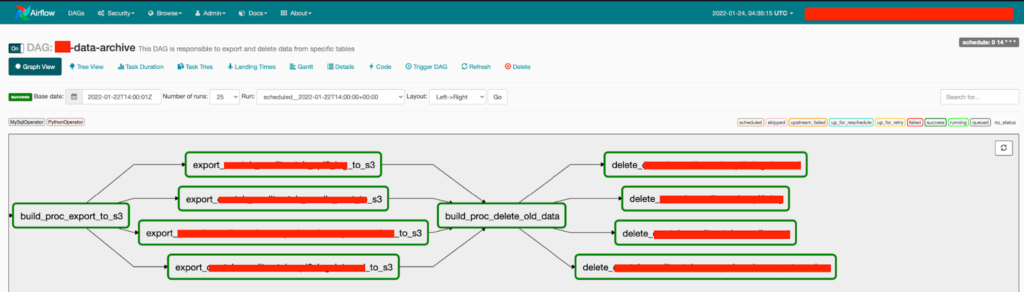
To encapsulate those tasks we use an Airflow DAG.
Airflow works with DAGs, DAG is a collection of all the tasks you want to run. A DAG is defined in a Python script, which represents the DAGs structure (tasks and their dependencies) as code.
In our scenario, the DAG will cover the following tasks:
- Task 1 – Build procedure to export data
- Task 2 – Execute procedure for export
- Task 3 – Build procedure to delete data
- Task 4 – Execute delete procedure
Airflow DAG graph
Creating a function to call a stored procedure on RDS
EXPORT_S3_TABLES = {
"id_1": {"name": "table_1", },
"id_2": {"name": "table_2" },
"id_3": {"name": "table_3"},
"id_4": {"name": "table_4"}
}
def export_data_to_s3(dag, conn, mysql_hook, tables):
tasks = []
engine = mysql_hook.get_sqlalchemy_engine()
with engine.connect() as connection:
for schema , features in tables.items():
run_queries = []
t = features.get("name") #extract table name
statement = f'call MyDB.SpExportDataS3("{t}")'
sql_export = (statement).strip()
run_queries.append(sql_export)
task = MySqlOperator(
sql= run_queries,
mysql_conn_id='mysql_default',
task_id=f"export_{t}_to_s3",
autocommit = True,
provide_context=True,
dag=dag,
)
tasks.append(task)
return tasks
To deploy the stored procedure we can use MySQL Operator that will be responsible for executing the “.sql” files as shown below
build_proc_export_s3 = MySqlOperator(dag=dag,
mysql_conn_id='mysql_default',
task_id='build_proc_export_to_s3',
sql='/sql_dir/usp_ExportDataS3.sql',
on_failure_callback=slack_failed_task,
)
Once the procedure has been deployed we can execute it using mysqlhook which will execute the stored procedure using the export_data_to_s3 function.
t_export = export_data_to_s3(dag=dag,
conn="mysql_default",
mysql_hook=prod_mysql_hook,
tables=EXPORT_S3_TABLES,
)
MWAA will orchestrate each SQL script that will be called on RDS, 2 stored procedures will be responsible for exporting and deleting the data consecutively. With this approach, all intensive work (read/process data) will be handled by the database and Airflow will work as an orchestrator for each event.
In addition, Aurora MySQL has a built-in function (INTO OUTFILE S3) that is able to export data directly to S3, that way we do not need another service to integrate RDS with the S3, the data can be persisted directly on the bucket once the procedure is called.
E.g: INTO OUTFILE S3
SELECT id , col1, col2, col3
FROM table_name
INTO OUTFILE S3 's3-region-name://my-bucket-name/mydatabase/year/month/day/output_file.csv'
FORMAT CSV HEADER
FIELDS TERMINATED BY ' ,'
LINES TERMINATED BY '\n'
OVERWRITE ON;
With this function we don’t need to handle the data with python scripts from Airflow, the data will be totally processed by the database and won’t be necessary create data transformation to output the data as CSV.
Conclusion
Airflow is a powerful tool that allows us to deploy smart workflows using simple python code. With this example, we demonstrated how to build a batch process to move the data from a relational database to S3 in simple steps.
There are an unlimited number of features and integrations that can be explored on MWAA, if you need flexibility and easy integration with different services (even non-AWS services), this tool can likely meet your needs.
DNX has the solutions and experience you need. Contact us today for a blueprint of your journey towards data engineering.


